TNEP model for the polarization#
This tutorial demonstrates how to train a tensorial neuroevolution potential (TNEP), as presented in Xu et al. (2024). We will train a model for predicting the polarization of bulk water using the data published alongside the paper, and use the model to run molecular dynamics. For predicting the IR spectrum from a trained TNEP model, see the Predicting IR spectra tutorial.
In short, TNEP extends the NEP formalism which predicts the per-atom energies \(U_i\) as a function of atom-centered descriptors \(q_i^\gamma\),
We can calculate the gradients of \(U_i\) to analytically obtain the partial force \(\partial U_i / \partial r_{ij}^\nu\), where \(r_{ij}^\nu\) is the \(\nu\)-component of the interatomic distance vector \(\boldsymbol{r}_{ij} = \boldsymbol{r}_j - \boldsymbol{r}_i\). The basis for predicting tensorial properties within the TNEP framework is the partial force and the rank-2 virial tensor \(W^{\mu \nu}\), denoted as
Rank-1 tensors such as the dipole \(\mathbf{\mu}\) or the polarization \(\mathbf{P}\) might naïvely be predicted based on the partial force directly. However, this does not work as the partial forces sum to zero per construction. To circumvent this problem, the TNEP framework draws inspiration from the atomic virial, and defines rank-1 tensors based on a contraction of the rank-2 virial tensor with a vector,
For rank-2 tensors such as molecular polarization \(\boldsymbol{\alpha}\) or electric susceptibility \(\boldsymbol{\chi}\), the virial tensor is slightly adapted for numerical stability,
\(\delta^{\mu \nu}\) is the Kronecker delta, and helps stabilize the prediction of rank-2 tensor as the diagonal elements often are large than the off-diagonal elements.
Loading the dataset#
We can obtain DFT training data of polarization structures for water from Zenodo, where we will obtain the file dipole_bulk_water.zip. The file is roughly 1.6MB in size. Note that the archive is named dipole_bulk_water.zip — a misnomer; the quantity modelled is the macroscopic polarization of the simulation cell, not a molecular dipole.
[1]:
import os, zipfile, urllib.request
url = 'https://zenodo.org/records/10257363/files/dipole_bulk_water.zip'
if not os.path.exists('tnep-tutorial/dipole_bulk_water'):
os.makedirs('tnep-tutorial', exist_ok=True)
urllib.request.urlretrieve(url, 'tnep-tutorial/dipole_bulk_water.zip')
with zipfile.ZipFile('tnep-tutorial/dipole_bulk_water.zip') as zf:
zf.extractall('tnep-tutorial/')
os.remove('tnep-tutorial/dipole_bulk_water.zip')
print('Downloaded and extracted dipole_bulk_water/')
else:
print('tnep-tutorial/dipole_bulk_water/ already present')
tnep-tutorial/dipole_bulk_water/ already present
We load the training and test structures using ASE.
[2]:
import warnings
warnings.filterwarnings('ignore', message='Failed to retrieve stresses for structure')
from ase.io import read
train_structures = read('tnep-tutorial/dipole_bulk_water/train.xyz', ':')
test_structures = read('tnep-tutorial/dipole_bulk_water/test.xyz', ':')
print(f'{len(train_structures)} structures in the training set, and {len(test_structures)} structures in the test set.')
500 structures in the training set, and 500 structures in the test set.
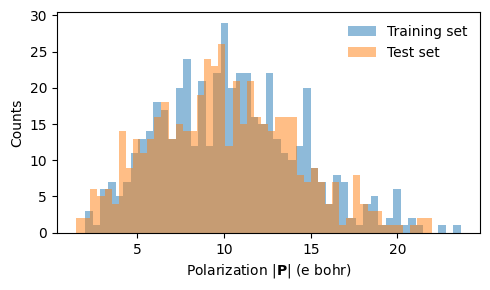
We can also inspect the polarization magnitudes:
[3]:
import numpy as np
import matplotlib.pyplot as plt
train_polarization_magnitudes = np.linalg.norm([structure.get_dipole_moment() for structure in train_structures], axis=1)
test_polarization_magnitudes = np.linalg.norm([structure.get_dipole_moment() for structure in test_structures], axis=1)
fig, ax = plt.subplots(figsize=(5, 3))
nbins = 50
ax.hist(train_polarization_magnitudes, bins=nbins, label='Training set', alpha=0.5)
ax.hist(test_polarization_magnitudes, bins=nbins, label='Test set', alpha=0.5)
ax.set(xlabel=r'Polarization $|\mathbf{P}|$ (e bohr)', ylabel='Counts')
ax.legend(loc='upper right', frameon=False)
fig.tight_layout()
Preparing training#
We can now use setup_training from calorine to prepare training of the model. The most important parameter is model_type=1, which signals to the nep executable that we aim to train a rank-1 tensorial model.
Note that lambda_1 and lambda_2 are set to 0.0005, well below the GPUMD default of 0.05. For TNEP models the output quantities (polarization components) are typically much smaller in magnitude than energies and forces, so the default regularization strength over-regularizes the tensor outputs and leads to underfitting; smaller values are therefore recommended. For an analysis of the effect of regularization on TNEP models see Figure S13 of the Supporting Information in Xu et al.
(2024).
Please refer to the GPUMD documentation for details on the remaining parameters.
[4]:
from calorine.nep import setup_training
# prepare input for NEP construction
parameters = dict(version=4,
type=[2, 'O', 'H'],
model_type=1,
cutoff=[6, 4],
n_max=[6, 6],
basis_size=[10, 10],
l_max=[4, 2, 1],
neuron=10,
population=80,
lambda_1=0.0005,
lambda_2=0.0005,
generation=50000,
save_potential=[5000, 0, 1],
batch=500)
setup_training(parameters, train_structures, rootdir='tnep-tutorial',
overwrite=True, mode='bagging', train_fraction=1)
The cell above sets up all required files for training in the tnep-tutorial/nepmodel_full directory. Next, one needs to go to tnep-tutorial/nepmodel_full and run nep in order to start the training. The training is computationally expensive and here with 500 training structures takes about 5 hours on an A100 GPU. A pre-trained polarization model is available from the same Zenodo record; it can be used directly for molecular dynamics
simulations and IR spectrum prediction as described in the Predicting IR spectra tutorial.
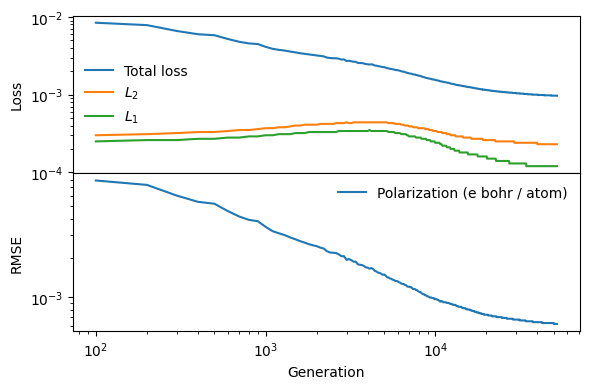
Analysis of the model#
We can now analyze the training of the model trained on all available data, nepmodel_full.
[5]:
from calorine.nep import get_parity_data, read_loss, read_structures
loss = read_loss('tnep-tutorial/nepmodel_full/loss.out')
fig, axes = plt.subplots(figsize=(6, 4), nrows=2, sharex=True)
ax = axes[0]
ax.set_ylabel('Loss')
ax.plot(loss.total_loss, label='Total loss')
ax.plot(loss.L2, label='$L_2$')
ax.plot(loss.L1, label='$L_1$')
ax.set_yscale('log')
ax.legend(frameon=False)
ax = axes[1]
ax.plot(loss.RMSE_P_train, label='Polarization (e bohr / atom)')
ax.set_xscale('log')
ax.set_yscale('log')
ax.set_xlabel('Generation')
ax.set_ylabel('RMSE')
ax.legend(frameon=False)
fig.tight_layout()
fig.subplots_adjust(hspace=0, wspace=0)
fig.align_ylabels(axes)
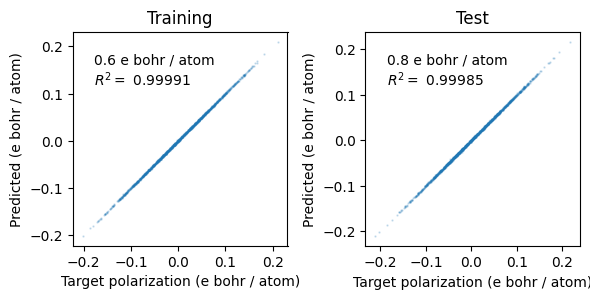
The parity plots below compare predicted and target polarization for the training and test sets. The root-mean-square error (RMSE) and coefficient of determination \(R^2\) are shown in each panel; values close to zero and one, respectively, indicate good model accuracy.
[6]:
from pandas import DataFrame
from calorine.nep import read_structures, get_parity_data
from calorine.calculators import CPUNEP
training_structures, _ = read_structures('./tnep-tutorial/nepmodel_full')
train_df = get_parity_data(training_structures, 'dipole', flatten=True)
# Evaluate the model on the test set to get predictions
test_structures = read('tnep-tutorial/dipole_bulk_water/test.xyz', ':')
test_polarization_targets = np.array(
[structure.get_dipole_moment()/len(structure) for structure in test_structures]
).flatten()
test_polarization_predictions = np.array(
[CPUNEP('./tnep-tutorial/nepmodel_full/nep.txt',
structure).get_dipole_moment() / len(structure)
for structure in test_structures]).flatten()
test_df = DataFrame(np.vstack(
[test_polarization_predictions, test_polarization_targets]).T,
columns=['predicted', 'target'])
[7]:
from sklearn.metrics import r2_score, mean_squared_error
unit = 'e bohr / atom'
fig, axes = plt.subplots(figsize=(6, 3), ncols=2)
kwargs = dict(alpha=0.2, s=0.5)
for icol, (df, label) in enumerate(zip([train_df, test_df], ['Training', 'Test'])):
R2 = r2_score(df.target, df.predicted)
rmse = np.sqrt(mean_squared_error(df.target, df.predicted))
ax = axes[icol]
ax.set_xlabel(f'Target polarization ({unit})')
ax.set_ylabel(f'Predicted ({unit})')
ax.set_title(label)
ax.scatter(df.target, df.predicted, **kwargs)
ax.set_aspect('equal')
mod_unit = unit.replace('eV', 'meV').replace('GPa', 'MPa')
ax.text(0.1, 0.75, f'{1e3*rmse:.1f} {mod_unit}\n' + '$R^2= $' + f' {R2:.5f}', transform=ax.transAxes)
fig.tight_layout()
Predicting the IR spectrum#
With a trained TNEP model and a PES model, an IR spectrum can be predicted from an NVE molecular dynamics trajectory. See the Predicting IR spectra tutorial for a complete walkthrough using the water model trained here.